XML is belangrijk en eenvoudig aan te leren.
Een voorbeeld:
<?xml version="1.0" encoding="utf-8"?> <nota> <voor>Tania</voor> <van>Jan</van> <titel>Geheugensteun</titel> <bericht>Stuur je me een verslag van de vergadering.</bericht> </nota>
XML staat voor eXtensible Markup Language.
XML is een markup taal zoals HTML.
XML is ontworpen om gegevens uit te wisselen en op te slaan.
XML tags zijn niet voorgedefinieerd. Je moet ze zelf definiëren.
XML is zelf beschrijvend.
XML is software- en hardware onafhankelijk.
XML wordt sedert 10 februari 1998 door W3C aanbevolen.
XML en HTML hebben elk hun eigen functie:
XML is ontworpen om gegevens uit te wisselen en op te slaan. De gegevens staan centraal.
HTML is ontworpen om gegevens weer te geven. De lay-out staat centraal.
HTML toont informatie, XML transporteert informatie.
XML is ontworpen om informatie te structureren, op te slaan en te transporteren.
De nota in het voorbeeld is zelf beschrijvend. Het heeft een afzender (van), een bestemming (voor), een titel en een tekstbericht.
M.a.w. dit XML document doet helemaal niets. Het wordt enkel gebruikt om informatie in tags op te slaan. Er zijn dus programma's nodig om XML te verzenden, te ontvangen en weer te geven.
De tags in het voorbeeld (zoals <voor> en <van>) maken geen deel uit van de XML standaard. Deze tags zijn verzonnen door de auteur van het XML document.
De XML standaard bevat dus geen voorgedefinieerde tags.
De tags die in HTML gebruikt worden, zijn voorgedefinieerd en maken deel uit van de HTML standaard.
De auteur van een XML document definieert zijn eigen tags en documentstructuur.
XML is vandaag even belangrijk voor het web als HTML bij het ontstaan van het web.
XML is de meest gebruikte manier om informatie tussen toepassingen uit te wisselen.
XML wordt meestal gebruikt om de opslag en het delen van gegevens op het web te vereenvoudigen.
Om dynamisch gegevens in een HTML document weer te geven, moet je niet telkens het HTML document aanpassen.
De gegevens worden opgeslagen in afzonderlijke XML bestanden. De HTML/CSS tandem zorgt dus enkel voor het weergeven en de lay-out, waardoor de onderliggende gegevens geen invloed meer hebben op de HTML en CSS code.
Met behulp van JavaScript wordt een extern XML bestand geladen en wordt de inhoud van de webpagina met de geladen gegevens uitgebreid en/of aangepast.
Computersystemen en databases bevatten gegevens in niet compatibele formaten.
XML gebruikt het platte tekst formaat. Deze methode is een software- en hardware onafhankelijke manier om gegevens op te slaan.
Dit maakt het veel eenvoudiger om gegevens die door verschillende toepassingen gebruikt worden op te slaan.
Eén van de meest tijdrovende uitdagingen voor ontwikkelaars is het uitwisselen van gegevens tussen niet compatibele systemen.
Gegevens uitwisselen in het XML formaat is een welkome vereenvoudiging.
Upgraden naar nieuwe systemen (hardware of software platforms) is steeds tijdrovend. Grote hoeveelheden gegevens moeten daarbij omgezet worden waarbij niet compatibele gegevens dikwijls verloren gaan.
XML gegevens zijn in tekstformaat opgeslagen. Dit maakt het veel eenvoudiger om zonder verlies aan gegevens over te stappen naar een ander besturingssysteem, andere toepassingen of een andere browser.
Verschillende toepassingen kunnen de gegevens raadplegen, niet enkel HTML pagina's maar ook diverse andere toepassingen.
XML maakt uw gegevens beschikbaar voor verschillende apparaten (van draagbare computers, spraakcomputers, nieuwslezers – feeds, enz.), ook voor apparaten en software voor blinden en andersvaliden.
De volgende Internet talen gebruiken XML als basis:
XHTML
WSDL om beschikbare webdiensten te beschrijven
WAP en WML als markup talen voor draagbare apparaten
RSS voor nieuwsberichten (news feeds)
RDF en OWL voor het beschrijven van bronnen en ontologieën
SMIL voor het beschrijven van multimedia op het web
Indien XML de standaard wordt om gegevens tussen toepassingen uit te wisselen, komen er in de nabije toekomst tekstverwerkers, rekenbladen en databanken die zonder conversie gegevens onderling kunnen uitwisselen.
XML documenten gebruiken een boomstructuur die bij de “stam” start en zich tot aan de “bladeren” vertakt.
Het voorbeeld:
<?xml version="1.0" encoding="utf-8"?> <nota> <voor>Tania</voor> <van>Jan</van> <titel>Geheugensteun</titel> <bericht>Stuur je me een verslag van de vergadering.</bericht> </nota>
De eerste regel is de XML declaratie. Het definieert de gebruikte XML versie (1.0) en de karakterset (utf-8).
De volgende regel beschrijft de stam (root element) van het document (dit document is een nota).
De volgende vier regels beschrijven vier bladeren (child elementen) van de root (voor, van, titel en bericht).
De laatste regel sluit het root element af.
Je kunt er dus vanuit gaan dat dit XML document een nota van Jan voor Tania bevat.
Dit is wat we bedoelen met zelf beschijvend.
XML documenten moeten een root element bevatten. Dit element is de ouder (parent) van alle andere elementen.
De elementen in een XML document vormen een documentboom. De boom start bij de root en vertakt zich verder tot het laatste niveau van de boom.
Alle elementen kunnen subelementen bevatten (child elementen):
<root>
<child>
<subchild>.....</subchild>
</child>
</root>
De termen parent, child en sibling worden gebruikt om de relaties tussen elementen te beschrijven. Parent elementen hebben children. Children in hetzelfde niveau noemen we siblings (broers en zussen).
Alle elementen kunnen zoals bij HTML tekst en kenmerken (attributes) bevatten.
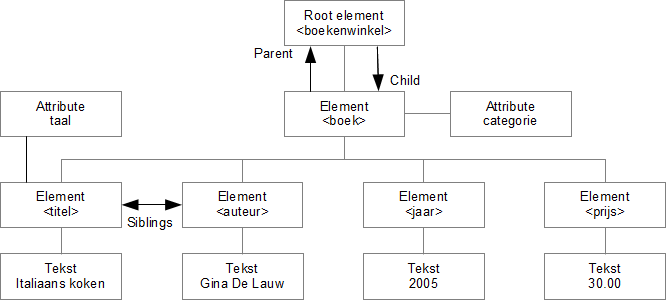
De afbeelding hierboven is een grafische voorstelling van onderstaand XML document:
<?xml version="1.0" encoding="utf-8"?> <boekenwinkel> <boek categorie="KOKEN"> <titel taal="nl">Italiaans koken</titel> <auteur>Gina De Lauw</auteur> <jaar>2005</jaar> <prijs>30.00</prijs> </boek> <boek categorie="KINDEREN"> <titel taal="nl">Harry Potter</titel> <auteur>J K. Rowling</auteur> <jaar>2005</jaar> <prijs>29.99</prijs> </boek> <boek categorie="WEB"> <titel taal="en">Learning XML</titel> <auteur>Erik T. Ray</auteur> <jaar>2003</jaar> <prijs>39.95</prijs> </boek> </boekenwinkel>
Het root element in het voorbeeld is <boekenwinkel>. Alle <boek> elementen staan binnen het <boekenwinkel> root element.
De syntaxis regels van XML zijn eenvoudig en logisch.
In HTML hebben sommige elementen geen afsluitende tag.
In XML moet elke tag afgesloten worden.
XML tags zijn hoofdlettergevoelig. De tag <boek> is niet hetzelfde als de tag <Boek>.
Openende (start) en afsluitende (eind) tags moeten dezelfde letters gebruiken:
<prijs>39.95</prijs>
Met correct genest bedoelen we dat een tag die binnen een andere tag wordt geopend, ook binnen dezelfde tag wordt gesloten.
<boek categorie="WEB"> <titel taal="en">Learning XML</titel> <auteur>Erik T. Ray</auteur> <jaar>2003</jaar> <prijs>39.95</prijs> </boek>
XML documenten bevatten een tag waarin alle andere elementen staan.
<titel taal="en">Learning XML</titel>
Sommige tekens hebben in XML een speciale betekenis.
Bij het gebruik van het teken “<” binnen een XML element krijg je een fout. De XML verwerker ziet dit namelijk als het begin van een nieuw element.
Dit veroorzaakt een fout:
<bericht>Lonen < 1000 krijgen</bericht>
Om een fout te vermijden, vervang je het “<” teken door een entity reference:
<bericht>Lonen < 1000 krijgen</bericht>
XML kent vijf voorgedefinieerde entity references:
|
< |
< |
Kleiner dan |
|
> |
> |
Groter dan |
|
& |
& |
Ampersand |
|
' |
' |
apostrof |
|
" |
" |
Aanhalingsteken |
De syntaxis voor XML commentaar is dezelfde als in HTML.
<!-- Dit is commentaar -->
HTML herleidt meerdere opeenvolgende witruimte karakters tot één spatie.
Bij XML zijn alle opeenvolgende witruimte karakters van betekenis.
Windows toepassingen slaan een nieuwe regel meestal op met twee tekens: carriage return (CR) en line feed (LF). OS X en Unix toepassingen slaan een nieuwe regel meestal op als een LF teken.
XML slaat een nieuwe regel op als een LF teken.
Een XML element is alles vanaf en inclusief de start tag tot en met de eind tag van een element.
Een element bevat:
Andere elementen
Tekst
Kenmerken (attributen)
Of een mengsel van de drie bovenstaande onderdelen.
<?xml version="1.0" encoding="utf-8"?> <boekenwinkel> <boek categorie="KINDEREN"> <titel taal="nl">Harry Potter</titel> <auteur>J K. Rowling</auteur> <jaar>2005</jaar> <prijs>29.99</prijs> </boek> <boek categorie="WEB"> <titel taal="en">Learning XML</titel> <auteur>Erik T. Ray</auteur> <jaar>2003</jaar> <prijs>39.95</prijs> </boek> </boekenwinkel>
In bovenstaand voorbeeld bevatten de elementen <boekenwinkel> en <boek> andere elementen. <boek> bevat daarnaast een attribuut (categorie = "KINDEREN"). <titel>, <auteur>, <jaar> en <prijs> bevatten tekst.
Namen van XML elementen voldoen aan de volgende regels:
Namen mogen letters, cijfers en andere tekens bevatten
Namen mogen niet beginnen met een cijfer of een leesteken
Namen mogen niet starten met de letters xml (of XML, Xml, enz.)
Namen mogen spaties bevatten.
Zorg voor beschrijvende namen. Namen met een underscore worden aangeraden: <naam_auteur>.
Zorg voor korte namen: <boek_titel>.
Gebruik geen – tekens, komma's, dubbele punten.
XML documenten hebben vaak een overeenkomstige database. Gebruik dezelfde namen in het XML document en de database.
Speciale tekens zoals éóà zijn toegelaten in XML, test de XML verwerker grondig met zulke tekens, niet alle XML verwerkers ondersteunen deze speciale tekens.
XML elementen kan je uitbreiden met extra informatie.
<boek categorie="WEB"> <titel taal="en">Learning XML</titel> <auteur>Erik T. Ray</auteur> <prijs>39.95</prijs> </boek>
Laten we veronderstellen dat je een toepassing hebt geschreven waarbij je de elementen <titel>, <auteur> en <prijs> gebruikt.
De auteur van het XML voegt achteraf een element met extra informatie toe:
<boek categorie="WEB"> <titel taal="en">Learning XML</titel> <auteur>Erik T. Ray</auteur> <jaar>2003</jaar> <prijs>39.95</prijs> </boek>
Uw toepassing zal nog steeds werken. M.a.w. XML documenten kunnen uitgebreid worden zonder de werking van een toepassing te storen.
De attributen verschaffen aanvullende informatie over een element.
Attributen bevatten informatie dat geen deel uitmaakt van de gegevens. Een voorbeeld: het bestandsformaat is geen deel van het gegeven, maar is belangrijk voor de software die het element moet behandelen:
<bestand type="gif">computer.gif</bestand>
Attributen staan steeds tussen enkele of dubbele aanhalingstekens:
<persoon geslacht="vrouw"> <persoon geslacht='vrouw'>
Indien een attribuutwaarde zelf aanhalingstekens bevat gebruik je enkele aanhalingstekens of entity references:
<gangster naam='Patrick "Le grand blond" Haemers'> <gangster naam="Patrick " Le grand blond" Haemers'>
<persoon geslacht="vrouw"> <voornaam>Ann</voornaam> <naam>Saelens</naam> </persoon> <persoon> <geslacht>vrouw</geslacht> <voornaam>Ann</voornaam> <naam>Saelens</naam> </persoon>
In het eerste voorbeeld is het geslacht een attribuut, in het tweede voorbeeld een element. Beide voorbeelden leveren dezelfde informatie.
Er zijn geen regels over wanneer je een attribuut of een element gebruikt. Mij lijkt het eenvoudiger om attributen te vermijden en steeds elementen te gebruiken.
Attributen hebben de volgende nadelen:
attributen kunnen maar één waarde hebben
attributen kunnen geen boomstructuur bevatten
attributen kun je niet eenvoudig uitbreiden
Attributen zijn daarenboven moeilijker te lezen en te onderhouden. Gebruik elementen voor gegevens, attributen voor informatie die niet relevant is voor de gegevens.
Mijn favoriete manier van werken:
<nota>
<datum>
<dag>10</dag>
<maand>01</maand>
<jaar>2012</jaar>
</datum>
<voor>Tania</voor>
<van>Jan</van>
<titel>Geheugensteun</titel>
<bericht>Stuur je me een verslag van de vergadering.</bericht>
</nota>
Soms worden ID referenties toegekend aan elementen. Deze ID's worden gebruikt om XML elementen te identificeren (juist zoals HTML ID's):
<berichten> <nota id="501"> <voor>Tania</voor> <van>Jan</van> <titel>Geheugensteun</titel> <bericht>Stuur je me een verslag van de vergadering.</bericht> </nota> <nota id="502"> <voor>Jan</voor> <van>Tania</van> <titel>Re: Geheugensteun</titel> <bericht>Doe ik.</bericht> </nota> </berichten>
Het id attribuut wordt gebruikt om de verschillende nota's te identificeren. Het is geen deel van de nota zelf.
Metadata (data over de data) sla je op als attributen, de data zelf als elementen.
Well Formed XML documenten hebben een correcte XML systaxis:
<nota> <voor>Tania</voor> <van>Jan</van> <titel>Geheugensteun</titel> <bericht>Stuur je me een verslag van de vergadering.</bericht> </nota>
Een Valid XML document is een Well Formed XML document die de regels van een Document Type Definition (DTD) volgt:
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE nota SYSTEM "nota.dtd"> <nota> <voor>Tania</voor> <van>Jan</van> <titel>Geheugensteun</titel> <bericht>Stuur je me een verslag van de vergadering.</bericht> </nota>
De DOCTYPE declaratie is een referentie naar een extern DTD bestand.
Het doel van een DTD is de structuur van een XML document vast te leggen. Het definieert een structuur aan de hand van toegelaten elementen:
<!DOCTYPE nota [ <!ELEMENT nota (voor,van,titel,bericht)> <!ELEMENT voor (#PCDATA)> <!ELEMENT van (#PCDATA)> <!ELEMENT titel (#PCDATA)> <!ELEMENT bericht (#PCDATA)> ]>
W3C ondersteunt een op XML gebaseerd alternatief voor DTD: XML Schema:
<xs:element name="nota"> <xs:complexType> <xs:sequence> <xs:element name="voor" type="xs:string"/> <xs:element name="van" type="xs:string"/> <xs:element name="titel" type="xs:string"/> <xs:element name="bericht" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element>
Met XSLT kan je een XML document omzetten naar HTML.
XSLT is de stijlpagina taal voor XML
XSLT (eXtensible Stylesheet Language Transformations) is veel geavanceerder dan CSS.
XSLT kan gebruikt worden om XML naar HTML om te zetten, voor het in de browser wordt weergeven.